5 Minuten Tipps: Magento Performance Tweaks

Meine “Woche auf StackExchange” Reihe pausiert gerade weil nicht sooo viel bloggenswertes wöchentlich zusammenkommt.
Stattdessen heute mal wieder etwas neues: Tipps zu einem bestimmten Themenbereich, die man sich in maximal 5 Minuten in der Kaffeepause durchsehen kann. Das meiste nicht von mir sondern nur von mir gefunden 🙂
Es soll keine regelmäßige Reihe werden, aber ich denke es kommt das ein oder andere zusammen, was ich bisher lose gesammelt habe. Da nutze ich doch mal wieder das Blog zum Festhalten von nützlichen Dingen und hoffe, es haben noch mehr Leute etwas davon.
Fangen wir an mit Magento Performance Tweaks, alle mit wenig Aufwand, die alle relativ bedenkenlos eingesetzt werden können:
Continue reading “5 Minuten Tipps: Magento Performance Tweaks”
Die Woche auf StackExchange #10 / 2016
Hier kommt das nächste Update zu neuen, hoffentlich interessanten, Fragen und Antworten auf StackExchange.
Neue Antworten
- Marius hat sich meiner Frage zu generierten PHTML Dateien in Magento 2 angenommen und auch herausgefunden, wann sie genutzt werden: When and how are phtml templates generated in view_pre geprocessed?
- Ich habe einen Bug in der JavaScript Funktion
Mage.Cookies.clear()gefunden. Offenbar hat sie noch nie funktioniert, im Core wird sie allerdings auch nicht genutzt. Hier beschreibe ich den Fix: Mage.Cookies.clear() not working - In How to limit characters in system.xml for textarea in magento zeige ich, wie einfach Validierung von Eingabefeldern in der Magento-Konfiguration möglich ist (Spoiler: Man braucht kein jQuery).
- Eine interessante Optimierungsmöglichkeit bietet sich, wenn man die URL Rewrites für Produkte nicht braucht: How do I get Magento to always give the /catalog/product/view/id/ style url for products?
- Ein Problem, das auch andere Magento-Nutzer kennen könnten, die Varnish mit HTTPS zum laufen bekommen wollen: https redirection loop even with X-Forwarded-Proto
Neue Fragen
- Ich habe mir die Frage gestellt, ob es als Extension-Entwickler Sinn macht, Magento komplett als dev-requirement zu definieren: Magento 2 as composer dev requirement for extensions – die Antwort ist wohl wie so oft “it depends”. Es war aber auf jeden Fall schon interessant, Einblicke z.B. von Aheadworks und Fooman zu bekommen.
- Auf How does translation scope work in Magento 2? hat immer noch keiner geantwortet und ich fürchte, das liegt daran dass es keine Antwort gibt. Sicherheitshalber habe ich mal ein Kopfgeld ausgesetzt. +50
EcomDev PHPUnit Tipp #13
Seit Jahren ist das Test-Framework EcomDev_PHPUnit quasi-Standard für Magento Unit Tests. Die aktuelle Version ist 0.3.7 und der letzte Stand der offiziellen Dokumentation ist Version 0.2.0 – seitdem hat sich viel getan, was man leider im Code und GitHub Issues selbst zusammensuchen muss. Diese Serie soll praktische Tipps zur Verwendung sammeln.
Tipp #13: EAV Fixtures beschleunigen
Nutzt man die EAV Fixtures, um Produkte, Kategorien und Kunden für Tests anzulegen, macht der Fixture Processor von EcomDev_PHPUnit vor jedem Test ein Backup der jeweils bestehenden Tabellen und spielt es anschließend wieder zurück. Da die “magento_unit_tests” Test-Datenbank standardmäßig als Kopie der aktuellen Magento-Datenbank angelegt wird, kann das sehr viel unnötiger Overhead sein.
Die EAV-Tabellen in der Test-Datenbank einmalig zu bereinigen, kann Tests, die sonst mehrere Minuten laufen um ein vielfaches beschleunigen. Dazu löschen wir in der Test-DB alle Datensätze in den Main Tables (die verknüpften Attribute etec. werden über Trigger automatisch gelöscht), mit Ausnahme der Standard Root Kategorie:
delete from catalog_product_entity; delete from catalog_category_entity where entity_id > 2; delete from customer_entity;
Zufällige Produkte in Magento anzeigen
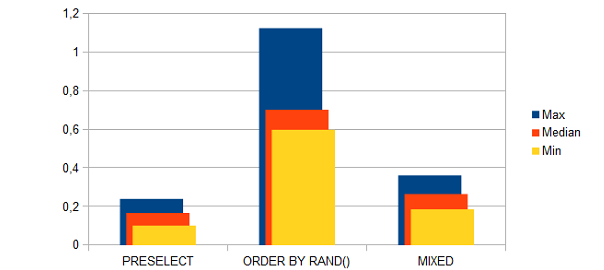
Leider ist der Eintrag nur auf Englisch verfügbar.
CSV-Verarbeitung in Magento
Ein Grundsatz bei der Entwicklung, nicht nur mit Magento, ist dass man nicht versuchen sollte, das Rad neu zu erfinden und insbesondere auf die Funktionen des verwendeten Frameworks zurückzugreifen, soweit möglich. Magento hat viele mehr oder weniger bekannte universelle Helfer, in den Helper-Klassen aus Mage_Core sowie unter lib/Varien, und natürlich im Zend Framework.
Ein Klassiker ist z.B. JSON Kodierung. PHP hat zwar built-in die Funktionen json_encode und json_decode, die haben aber einige Unzulänglichkeiten, die in der Implementierung von Zend_Json ausgebügelt wurden. So gibt es in Zend_Json::encode() einen Zyklen-Check. Magento hat in Mage_Core_Helper_Data::jsonEncode() noch Support für Inline-Translations innerhalb von JSON hinzugefügt.
In Magento sollte man also immer Mage::helper('core')->jsonEncode() (bzw. jsonDecode) benutzen.
Varien_File_Csv
Und wie sieht es bei der Verarbeitung von CSV Dateien aus? Da der import und Export im Standard mit CSV Dateien funktioniert, sollte Magento doch etwas haben… Vorhang auf für Varien_File_Csv. Naja, ich nehme das Ergebnis mal vorweg: außer bei ganz einfachen Aufgaben mit kleinen Dateien ist die Klasse nicht zu gebrauchen.
PHP: Referenzen und Speicher
Nutze niemals Referenzen in PHP, nur um Speicherbedarf zu reduzieren. PHP handhabt das bereits mit seinem internen copy on write Mechanismus.
Beispiel:
$a = str_repeat('x', 100000000); // Memory used ~ 100 MB
$b = $a; // Memory used ~ 100 MB
$b = $b . 'x'; // Memory used ~ 200 MB
Du solltest Referenzen nur nutzen, wenn Du genau weißt, was du tust und sie für Funktionalität benötigst. Das ist fast nie der Fall, so dass man sie auch getrost völlig ignorieren kann. PHP-Referenzen sind im Allgemeinen eigenwillig und können in unerwartetem Verhalten resultieren.
Große PHP-Arrays, SPL und Sessions
Folgende Problemstellung: eine große Datenmenge wird auf einmal abgefragt, soll aber nicht direkt komplett an den Client gesendet werden, also wird sie in der Session zwischengespeichert. Vielleicht im allgemeinen nicht die geschickteste Lösung, in meinem Fall fielen die Nachteile jedoch nicht ins Gewicht. “Groß” bedeutete dabei im Bereich von 10-50 MB in 50K-100K Datensätzen.
Das ist nun leider eine Menge, bei der PHP-Arrays nur noch mit Vorsicht einzusetzen sind. Der Flaschenhals war in diesem Fall array_shift(), womit Einträge aus dem in der Session befindlichen Arrays entnommen wurden. Was läge da näher, als auf eine der SPL-Datenstrukturen zurückzugreifen? Leider sind sowohl SplStack als auch SplFixedArray nicht serialisierbar und somit nicht ohne Weiteres mit Sessions zu gebrauchen.
Dies lässt sich nachrüsten, dabei muss allerdings doch wieder auf PHP-Arrays zurückgegriffen werden. Mit dem Performance-Verlust beim Serialisieren und Deserialisieren erkauft man sich allerdings eine deutlich effizientere Daten-Verarbeitung. In meinem Fall war SplStack bzw. SplDoublyLinkedList perfekt, da die Daten nur noch der Reihe nach abgeholt werden sollten. Die Erweiterung sieht wie folgt aus:
Serialisierbare SPL-Datenstruktur
class SerializableList extends SplDoublyLinkedList
{
private $_data;
public function __sleep()
{
$this->_data = array();
$this->rewind();
while ($this->valid()) {
$this->_data[] = $this->current();
$this->next();
}
return array('_data');
}
public function __wakeup()
{
foreach ($this->_data as $row) {
$this->push($row);
}
$this->_data = array ();
}
}
Kurz erkärt
Beim Serialisieren (__sleep()) wird die Datenstruktur in ein PHP-Array (im Attribut _data) konvertiert und mit return array('_data') festgelegt, dass genau dieses Attribut serialisiert werden soll. Beim Deserialisieren (__wakeup()) ist _data wiederhergestellt und kann zurück konvertiert werden. Anschließend wird mit $this->_data = array() der Speicher wieder freigegeben.
Vorsicht
Ob diese Lösung im konkreten Fall sinnvoll ist, kann nur durch eigene Messungen ermittelt werden. Dabei sollte vor allen Dingen darauf geachtet werden, die Anzahl der Serialisierungsvorgänge so gering wie möglich zu halten, denn wie schon gesagt sind die durch die zusätzliche Konvertierung teurer als zuvor. Als Beispiel: Bei 8 Abfragen a 10000 Datensätzen war meine Anwendung mindestens 20 mal schneller als bei 80 Abfragen a 1000 Datensätzen. Und beide Varianten schlagen die Implementierung nur mit PHP-Arrays um Längen.
Eine Herausforderung für weitere Optimierung wäre es noch, einen eigenen Serialisierer zu schreiben, der ohne PHP-Array auskommt. Das wäre allerdings eher etwas für die PECL, sprich direkt in C gehackt. In PHP selbst sehe ich da wenig Hoffnung in puncto Effizienz.